







みなさまはLogsInsightsで
ログ解析をされますでしょうか?
そのなかで、parseコマンドを使っていますでしょうか。
AWS基盤のシステムでログ調査を行う際、
LogsInsightsを使うことが多いと思います。
ログ内容はログ設計次第で
かなり見やすさが変わるものかと思います。
すべてが見やすいログ設計であると
解析作業をする身としては嬉しいです。
が、そういうわけにもいかないです。
もちろん、システムによっては少々解析しにくいログも存在しています。
そこで今回は、LogsInsightsで
シンプルな文字列ログを解析するのに役立つコマンドを
サンプル付きで紹介していきます。
parseコマンドとstatsコマンドってなにもの?
クエリコマンドに関する説明は
以下の公式ドキュメントで紹介されています。
その中でparseコマンドとstatsコマンドについては、
それぞれ以下のように説明されています。
CloudWatch Logs Insights のクエリ構文
stats
statsを使用して、ログフィールド値で集約統計を計算します。parse
parseを使用して、ログフィールドからデータを抽出し、クエリで処理できるエフェメラルフィールドを作成します。
文章を読むだけじゃイメージ沸かない、という方…。私もそうでした。
なので自分の中で噛み砕いで実践的に
理解した内容をアウトプットしたいと思います。
サンプルログを使ってparseとstatsの実例を解説します
例えば死活監視として定期的に
HTTPステータスを拾っているアプリがあるとします。
そのアプリケーションは
下記のようなログメッセージを出力しています。
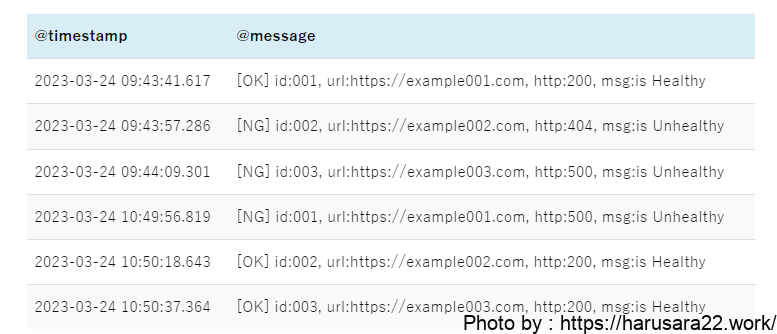
このログ文字列をパターン別に解析してみようと思います。
parseコマンドで文字列を分割する
まずログ文字列を集計可能な情報単位に分割したいです。
そのために、parseコマンドを使います。
先ほどのサンプルログを
情報単位に分割するためには、
下記クエリを実行します。
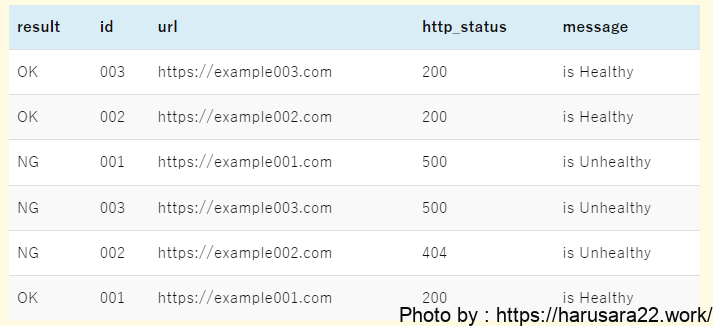
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| display result, id, url, http_status, message- 1行目の
parseコマンドですが、ざっくりと説明すると正規表現を使用して抜き取りたい情報を新しいフィールド名に定義し直しています。
本クエリでは@messageフィールドに存在する文字列のうち、*(アスタリスク)に該当する文字列をas句以降に定義した名前で新しいフィールド名を作成します。 - 続けて2行目ですが、しれっと
displayコマンドを使っています。
今回の使い所でいうと、1行目のparseコマンドのas句以降のフィールドを表示用に指定しているクエリになります。
今回しれっと使ったdisplayコマンドは
公式ドキュメントで下記の通り解説されています。
本記事でも今後度々活用します。
CloudWatch Logs Insights のクエリ構文
display
displayを使用して、クエリ結果の特定のフィールドを表示します。
特定の@messageだけparseしたい場合
ログにはparseしたい文字列以外の
フォーマットも混ざっているかもしれません。
例えば下記のように、開始と終了が記録されているログがあるとします。
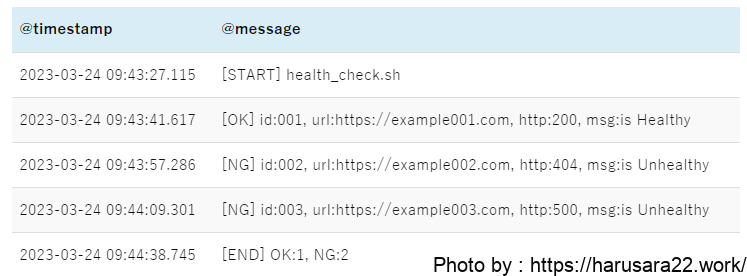
もしこのようなログの中で
特定のメッセージのみparseしたい場合は、filterコマンドを付け足しましょう。
下記はfilterコマンドの条件を使用したサンプルになります。
filter @message =~ /(\[OK\]|\[NG\])/
| parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| display result, id, url, http_status, message- クエリ①「文字列分割クエリ」の1行目に
filterコマンドを足しています。=~ /(\[OK\]|\[NG\])/は正規表現による条件指定を実施しており、ログメッセージ内に[OK]あるいは[NG]が含まれているメッセージのみを抽出するように条件指定しています。
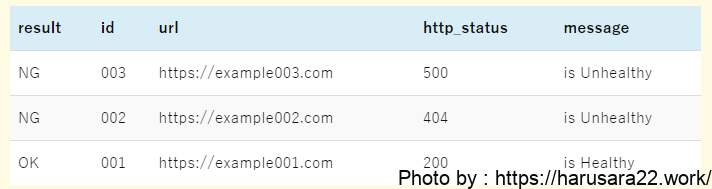

filterで絞り込んだので、クエリ①と同じ結果が出力されるようになりました。
statsコマンドで分割した情報を集計する
無事、parseコマンドで文字列から
情報を分割し抽出できるようになりました。
この抽出した情報をstatsコマンドを使ってパターン別に集計してみようと思います。
HTTPステータス別の監視結果数を集計したい
まずはシンプルにHTTPステータス別の集計を実施したいと思います。
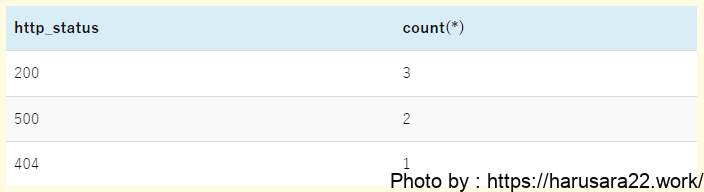
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats count(*) by http_status- 1行目の
parseコマンドは先ほど使用したものを同じクエリを流用します。
今後の集計クエリにおいても、このparseコマンドは同じものを使用していきます。 - 2行目の
statsコマンドで、HTTPステータス別のcount数を集計しています。
by句に指定しているhttp_statusは、1行目のparseコマンドで抜き取ったHTTPステータスそのものが格納されています。
一時間ごとの監視結果を単一のHTTPステータス別に集計したい
先ほどまでのクエリ①〜③では
クエリ上での条件で時間指定を行なっていないため、
LogsInsights側の指定時間範囲内で集計が行われていました。
これを、傾向や推移を確かめるために一時間単位の集計クエリへ変更したいと思います。
まずは特定の単一HTTPステータスで一時間単位の集計クエリを書いてみます。
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| filter http_status = 200
| stats count(*) by bin(1h)- クエリ③「シンプルな集計クエリ」との差分は下記2点です。
filterコマンドの追加statsコマンドのby句をbin(1h)に変更
- 言い換えると、先ほどの
stats count(*) by http_statusでは「HTTPステータス別に集計してね」でしたが、今回のstats count(*) by bin(1h)で「一時間毎に集計してね」という指示に変わったというわけです。 - ただし、無作為に「一時間毎に集計してね」としても「なにを??」となるのが明白です。なので、
statsコマンドの前にfilterコマンドで集計したいmessageを絞り込んでいます。
なお、filterコマンドを使わずに下記のようなクエリでも同様の結果が得られます。
各々の好みですが、こちらの方がスッキリして見やすいかもですね。
parse @message '[*] id:*, url:*, http:*, error_no:*, msg:*' as result, id, url, http_status, message
| stats sum(http_status = 200) by bin(1h)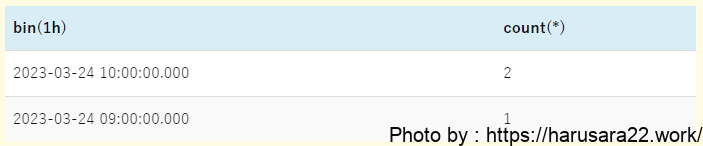
bin(1h)が一時間単位を示しています。一時間単位以外にも一日単位や15分単位といった刻み方で集計が可能です。
一時間ごとの監視結果を複数のHTTPステータス別に集計したい
次に、単一HTTPステータスの場合の集計クエリを応用して、
複数のHTTPステータスをまとめて集計したい場合のクエリを書いてみます。
こちらはクエリの書き方によって集計条件を縦軸にまとめる方法と、
集計条件を縦軸と横軸にわけてまとめる方法がありますので、
それぞれ記載していきます。
集計条件を全て縦軸に収める場合
まずは、集計条件を全て縦軸に収めても構わないクエリです。
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats count(*) as count_num by http_status, bin(1h) as bin_1h
| sort bin_1h, http_status- クエリ④「単一HTTPステータスの場合の集計クエリ」との差分は下記です。
statsコマンドのby句でbin(1h)に加えてhttp_statusを追加
statsコマンドのby句は複数フィールドが指定できます。
これを使用し、「HTTPステータスを一時間単位に集計してね」という複数指示が可能になります。- なお、
stats count(*) as count_numでas句を指定していますが、必須ではありません。
as句で別名定義しておくことでsortコマンドやdisplayコマンドで扱えるようになりますので、つけておいて損はないです。
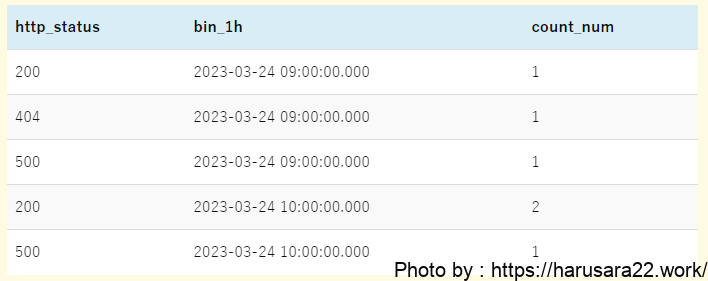
出力結果の列の並び順を調整したい場合はdisplayコマンドを使いましょう。
例えば、上記のクエリにdisplayコマンドを指定して列を入れ替えるだけでも見やすさが変わってくると思います。
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats count(*) as count_num by http_status, bin(1h) as bin_1h
| sort bin_1h, http_status
| display bin_1h, http_status, count_numこのクエリの場合の出力結果は下記に変わります。
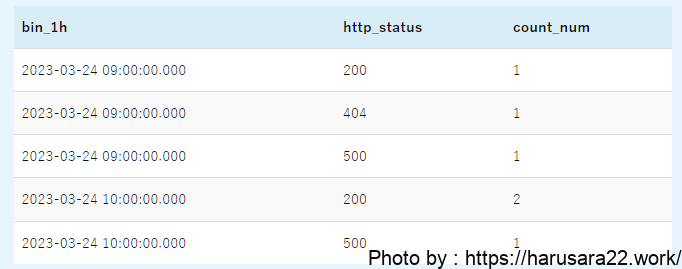
集計条件を縦軸と横軸にわける場合
では、クエリを少し書き換えて
マトリクス表のような出力結果を
アウトプットしようと思います。
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats
sum(http_status = 200) as count_200,
sum(http_status = 404) as count_404,
sum(http_status = 500) as count_500 by http_status, bin(1h) as bin_1h
| sort bin_1h, http_status
| display bin_1h, count_200, count_404, count_500- クエリ⑤「複数条件を縦軸にまとめた場合の集計クエリ」との主な差分は下記です。
statsコマンドでHTTPステータス別にsum関数での集計を追加
statsコマンドで条件別の集計を実施することで、その集計結果がそれぞれ列ごとに表示されるようになります。- なお上記クエリ内でもそれぞれas句で別名定義していますが、こちらもas句は必須ではありません。
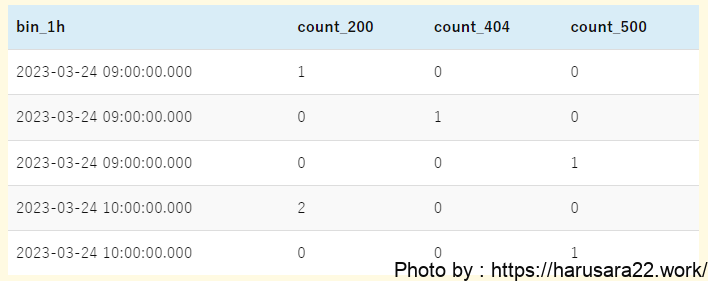
URL別にHTTPステータスを集計したい
先ほどまでのクエリでは、
HTTPステータスのみを集計していました。
これを、さらにURL別に集計したいと
なった場合のパターンを見ていきたいと思います。
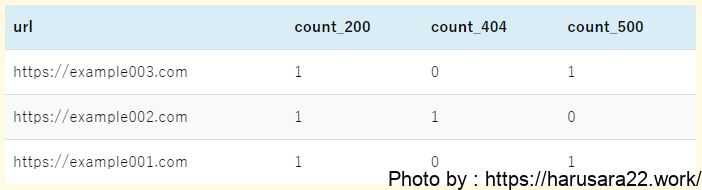
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats
sum(http_status = 200) as count_200,
sum(http_status = 404) as count_404,
sum(http_status = 500) as count_500 by url- これまでのHTTPステータスのみを集計していたクエリとの差分は下記です。
statsコマンドでhttp_statusをsum関数で集計を実施statsコマンドのby句をurlに変更
- これまではHTTPステータス別の集計だったのでby句に
http_statusを指定し「HTTPステータス別に集計してね」という指示をだしていました。
ここに「URL別にも集計したいなあ」となった場合は、statsコマンド内のsum関数の集計とby句の指定が肝になってきます。 - 言い換えると、本クエリでは「HTTPステータス別の集計結果をURL単位で見せてね」ということを指示しています。
一時間ごとに特定URLのHTTPステータスを集計したい
では、URL別の集計クエリも傾向や推移を確かめるために
一時間単位の集計クエリに変更したいと思います。
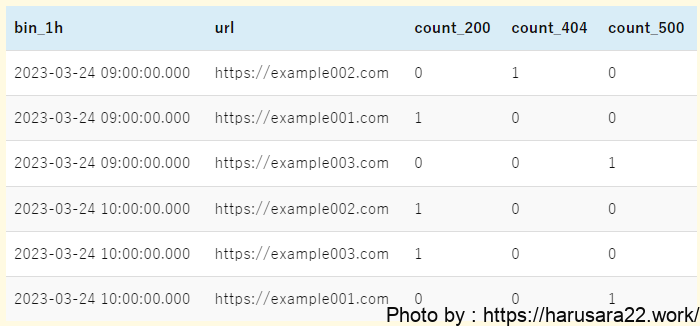
parse @message '[*] id:*, url:*, http:*, msg:*' as result, id, url, http_status, message
| stats
sum(http_status = 200) as count_200,
sum(http_status = 404) as count_404,
sum(http_status = 500) as count_500 by url, bin(1h) as bin_1h
| sort bin_1h, http_status
| display bin_1h, url, count_200, count_404, count_500- クエリ⑦「URL別にHTTPステータスを集計したクエリ」との差分は下記です。
statsコマンドのby句でurlに加えてbin(1h)を追加displayコマンドでbin(1h)とurl、statsコマンドの集計情報を必ず記載
statsコマンドにてsum関数による集計及びby句での複数フィールド指定を活用した、これまで紹介してきたクエリの集大成です。- こちらも言い換えると、「HTTPステータス別の集計結果を一時間毎にURL単位で見せてね」ということを指示しています。
最後に
いかがでしたでしょうか?
LogsInsightsのクエリは
公式ドキュメントを読んでいても
どことなく応用的に使えなかったため、
ちゃんと時間をかけて踏み込もうとしないと
なかなか理解力が深まらないなと感じました。
本記事がLogsInsightを使ったログ調査を
もっと捗らせたい方々の参考になりましたら幸いです。









余談ですが、json形式で出力されているログはデータとして扱いやすいけど、シンプルな文字列のみのログは解析目線だと扱いにくいなと思います。