



お疲れ様です。
はるさらと申します。
最近、業務や個人の制作活動で「生成AI」という言葉を耳にしない日はありません。
ChatGPTやGeminiなど、指示文(プロンプト)一つで文章作成からプログラミング、画像生成までこなしてくれるツールは非常に魅力的です。
しかし、便利な道具には必ず使いこなすための知識が必要です。
特にIT業界やクリエイティブな仕事に携わり始めたばかりの方にとって、
生成AIの「裏側にあるリスク」を知らずに使い続けることは、
思わぬトラブルを招く原因になりかねません。
この記事では、生成AIを安全に、そして最大限に活用するために
知っておくべきリスクと注意点を、具体的な事例や対策を交えて詳しく解説します。
生成AIを正しく理解し活用するための第一歩
生成AIを導入する際、最も重要なのは「何でもしていい魔法の杖」と勘違いしないことです。
生成AIは、従来のITシステムのように
「あらかじめ決められた処理を正確に行う」ものとは根本的に異なります。
AIは膨大なデータから学習し、次に続く言葉や画素を
「確率的に」予測して出力しているに過ぎません。
そのため、私たちが期待する正解を必ず出してくれるとは限らないのです。
この性質を理解していないと、AIがもっともらしく出力した誤情報を信じ込んでしまったり、
気づかないうちに機密情報を流出させてしまったりするリスクが高まります。
生成AIを「有能だが、時々嘘をつくアシスタント」として捉え、
人間が最終的な責任を持つというスタンスが、これからのITリテラシーには不可欠です。
例えば、新しいプログラミング言語の文法をAIに聞いたとき、
存在しないライブラリの使い方を堂々と提示されることがあります。
これをそのままプロジェクトに組み込んでしまうと、
バグの原因を特定するのに膨大な時間を費やすことになります。
まずは「リスクがあること」を前提に、一歩引いた視点で活用を始めることが、
安全な活用の第一歩となります。
必ず押さえるべき4つの主要リスク

生成AIを利用する上で避けては通れないリスクは、大きく分けて4つあります。
これらはどのような職種であっても共通する課題です。
ハルシネーション(幻覚)による誤情報の拡散
生成AIを利用する際、最も頻繁に遭遇するのが「ハルシネーション」と呼ばれる現象です。
ハルシネーションとは、AIが事実に基づかない情報を、
あたかも真実であるかのように自信満々に出力することを指します。
これはAIが「内容を理解している」のではなく、
単に「それっぽい言葉の並び」を作っているために起こります。
具体的な例を挙げると、歴史上の人物について尋ねた際に、
実在しないエピソードを詳細に語り始めたり、最新の法律について質問した際に、
古い情報や架空の条文を回答したりすることがあります。
経験の浅い方がこれを鵜呑みにしてブログ記事を書いたり、
顧客への報告資料を作成したりすると、情報の信頼性を著しく損なう結果となります。
対策としては、AIの回答を必ず一次ソース(公式ドキュメントや信頼できるニュースサイトなど)で確認する「ファクトチェック」を習慣化することが挙げられます。
AIは「下書き」を作るのには適していますが、
「事実の確認」を任せるにはまだ早い段階にあると考えるべきです。
プロンプト入力による機密情報の漏洩
業務で生成AIを使う際に、最も警戒しなければならないのが情報漏洩のリスクです。
私たちがAIに入力したテキスト(プロンプト)は、多くの場合、
AIモデルのさらなる学習に利用されたり、サービス提供側のサーバーに保存されたりします。
もし、顧客の個人情報や自社の未発表プロジェクトのソースコードをそのまま入力してしまうと、
それらが巡り巡って他のユーザーへの回答として出力されてしまう可能性がゼロではありません。
例えば、プログラムのバグを修正してもらうために、
社外秘のロジックが含まれたコードをそのままChatGPTに貼り付けるような行為は非常に危険です。
たとえ悪意がなくても、入力した時点でその情報は「外部に提供されたもの」として扱われるリスクがあります。
これを防ぐためには、個人情報や機密情報は絶対に直接入力しないという鉄則を守る必要があります。
どうしても特定のロジックを相談したい場合は、変数名を一般的なものに変える、
機密性の高い部分をダミーデータに置き換えるといった「情報の匿名化」を徹底してください。
著作権侵害と法的な権利関係
生成AIが作成した文章や画像が、既存の著作物と酷似してしまうことで、
意図せず著作権を侵害してしまうリスクがあります。
生成AIはインターネット上の膨大なデータを学習材料としています。
その中には当然、他者が著作権を持つ画像や記事も含まれています。
AIが生成したコンテンツが、特定の作家の作品と非常に似通っていた場合、
それを商用利用することで訴訟トラブルに発展する恐れがあります。
特に画像生成AIを利用してロゴやイラストを作成する場合、
有名なキャラクターや特定のアーティストの作風を強く意識したプロンプトを入力すると、
侵害のリスクが高まります。
また、生成された画像の中に、他社の商標やロゴが紛れ込んでしまうケースも報告されています。
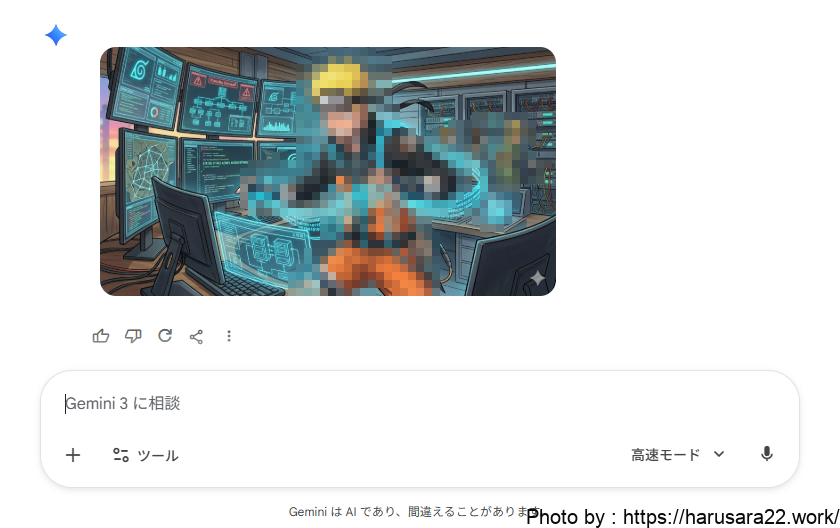
某忍者の名前を含めてしまうと
類似のイラストが
簡単に作成できてしまう
安全に利用するためには、生成物の公開前に画像検索などで類似のものがないか確認する。
あるいは利用規約を詳細に確認し、商用利用が認められている範囲内で活用することが求められます。
法律は常に変化しているため、最新のガイドラインをチェックする姿勢も重要です。
倫理的バイアスと不適切な表現
AIが出力する内容に、差別的、暴力的、あるいは偏った思想が
含まれてしまう「バイアス問題」も無視できません。
AIの学習データは人間が作った社会のデータであるため、
そこに含まれる偏見やステレオタイプをAIがそのまま学習してしまいます。
その結果、性別や人種、職業に対して偏った見解を回答として出力してしまうことがあります。
例えば、特定の職業のイラストを生成させたときに、
特定の性別や人種ばかりが表示されるといった現象がこれに当たります。
また、悪意のある問いかけに対して、社会的に不適切なアドバイスを生成してしまう可能性もあります。
これらをそのまま公開することは、企業のコンプライアンスに関わるだけでなく、
社会的な信用を失うことにもつながります。
AIの回答には常に「倫理的な偏りがないか」という人間の目による監視が必要です。
生成AI利用時の注意点:陥りやすい落とし穴

主要なリスク以外にも、実務で使い始める際に注意すべき細かなポイントがいくつかあります。
最新ニュースや法改正への非対応
生成AIは「学習が完了した時点までのデータ」しか持っていないことが多いため、
最新の情報には対応できないという弱点があります。
昨日のニュース、今朝発表された新しいIT技術、
あるいは先月施行されたばかりの法律についてAIに尋ねても、
それらしい嘘(ハルシネーション)をつかれるか、
古いデータに基づいた回答が返ってくることになります。
例えば、プログラミング時に最新のライブラリのバージョンアップに伴う変更点についてAIに相談すると、
廃止された古いメソッドを提案されることがよくあります。
新しい情報の収集には、AIではなく検索エンジンや技術コミュニティを活用するのが正解です。
論理過程のブラックボックス化
AIがなぜその結論に至ったのか、そのプロセスが不透明であるという点も注意が必要です。
AIの回答には、根拠となる資料の提示がないことが一般的です。
そのため、提示された回答が「正解に見えるだけ」なのか
「論理性に基づいている」のかを判断するのが非常に困難です。
システム設計などの重要な意思決定をAIの回答だけで行うと、
後で問題が発生した際に「なぜこの設計にしたのか」を説明できなくなります。
結論に至るまでのロジックは、必ず人間が自分の言葉で説明できるように整理しておく必要があります。
安全に使いこなすための具体的対策サンプル
リスクを理解したところで、実際にどのように対策を講じれば良いのか、
具体的なアクションプランを提案します。
社内ガイドラインの運用イメージ
組織で生成AIを利用する場合、まずは明確なルール作りが必要です。
以下は、利用規約やガイドラインに盛り込むべき項目のサンプルです。
- 許可されたツール以外は業務で利用しない
- プロンプトに個人情報(氏名、住所、電話番号等)を入力しない
- 顧客から預かったデータや機密情報は入力禁止とする
- AIが生成したプログラムコードは、必ず動作確認とコードレビューを行う
- 生成物をそのまま公開せず、必ず人間が内容の正確性を確認する
こうしたルールを設けることで、個人の判断ミスによる大きな事故を防ぐことができます。
セキュアな環境の選択
無料版の生成AIサービスは、入力データが学習に再利用される設定がデフォルトになっていることが多いです。
業務で利用する場合は、設定で「学習に利用しない」を選択するか、
法人向けの有料プラン、あるいはAPI経由での利用を検討してください。
例えば、ChatGPTの「Temporary Chat」機能や、
Google Geminiの「プライバシー設定」を確認し、
データがどのように扱われるかを把握することが重要です。
企業によっては、Azure OpenAI Serviceなどのように、
よりセキュリティが強固なプラットフォームを採用している場合もあります。
ヒューマン・イン・ザ・ループの徹底
「AIの出力」と「最終的な成果物」の間に、
必ず「人間の判断」を挟む運用フローを構築しましょう。
これを「Human-in-the-Loop」と呼びます。
具体的には、以下のようなステップを踏むことをお勧めします。
- AIに下書きやアイデアを出させる
- 人間がその内容の真偽を複数のソースで確認する
- 倫理的に問題がないか、自社のトーン&マナーに合っているか修正する
- 必要に応じて専門家(上司や法務担当など)のチェックを受ける
このプロセスを省かないことが、結果として最も効率的で安全な活用方法となります。
各ツールの学習機能をオフにする具体的な手順
生成AIを安全に使いこなすための対策の一つが、
入力した情報をAIの再学習に利用させない「オプトアウト」の設定です。
多くのサービスでは、ユーザーが入力した内容をAIモデルの性能向上のために
再利用する設定が標準で有効になっています。
これをオフにすることで、入力したデータが将来的に他のユーザーへの回答として
流用されるリスクを物理的に遮断できます。
主要な2つのツールについて、具体的な手順を確認しておきましょう。
ChatGPTでモデルの改善を無効化する方法
ChatGPTにおいて入力データを学習に使わせないためには、
設定メニューからデータコントロールを変更します。
手順は以下の通りです。
設定→データコントロール→「すべての人のためにモデルを改善する」をクリック
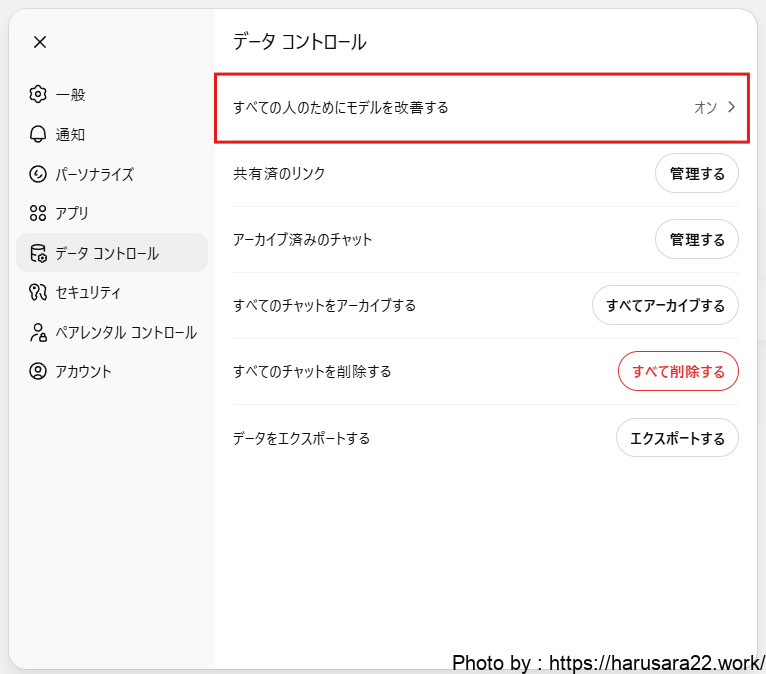
「すべての人のためにモデルを改善する」のボタンをOFFに切り替える。
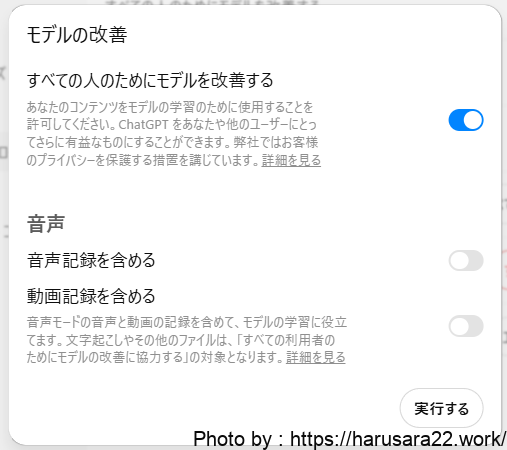
この設定をオフにすることで、以降の会話内容がOpenAI社のモデル学習に利用されることはなくなります。
以前はチャット履歴の保存と学習のオフが連動していましたが、現在の仕様では履歴を残しつつ学習だけを止めることが可能です。
また、特定の会話だけを履歴に残したくない場合は、
「一時的なチャット(Temporary Chat)」を選択するのも有効な手段です。
このモードでは、ブラウザのシークレットモードのように、
会話が終了した後に内容が保持されず、学習にも利用されません。

Google Geminiでアクティビティを無効化する方法
Google Geminiを利用する場合も、アクティビティの管理画面から学習の設定を変更できます。
具体的な操作手順は以下の通りです。
設定とヘルプから「アクティビティ」をクリック
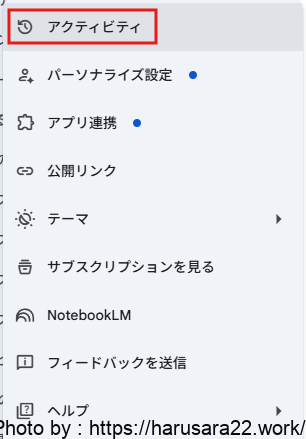
アクティビティの保存をオフに切り替える。
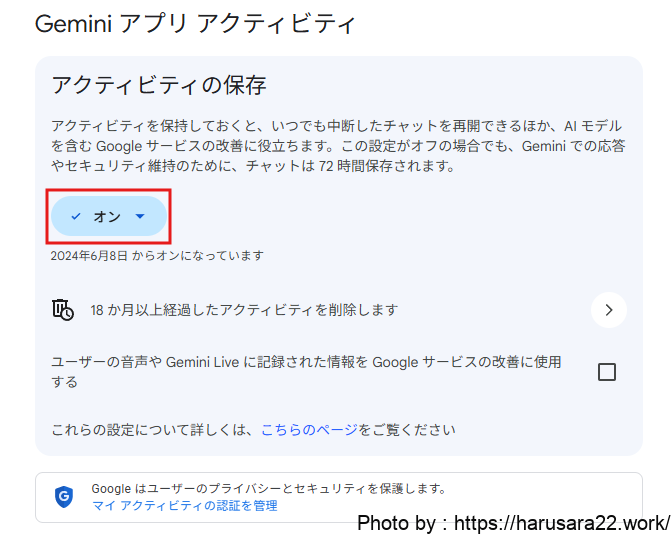
この設定をオフにすると、入力したプロンプトや生成された回答がGoogleアカウントに保存されなくなり、AIモデルの改善にも利用されなくなります。
設定をオフにした後の会話は、システム上のフィードバック対応などのために最大72時間保持されますが、それ以降は自動的に削除される仕組みになっています。
ただし、設定をオフにする前にやり取りした過去の履歴はそのまま残っているため、
必要に応じて「削除」メニューから過去のデータを消去しておくことも忘れないでください。
まとめ:生成AIをパートナーとして活用するために
生成AIは、正しく扱えば私たちの業務効率を劇的に向上させてくれる強力な味方です。
しかし、これまで見てきたように、情報の不正確さや情報漏洩、
法的リスクといった側面も持ち合わせています。
「正しく恐れる」という言葉がありますが、これは生成AIにも当てはまります。
リスクを過度に恐れて活用を諦めるのではなく、
どのようなリスクがあるかを具体的に把握し、
適切な対策を講じることで、AIはあなたのスキルを補完するパートナーになります。
特に経験の浅い方にとっては、AIとの対話を通じて新しい知識を得る機会も多いでしょう。
その際は、AIを「答えを教えてくれる先生」ではなく「一緒に考えるアシスタント」として
使い、最終的な判断の主導権を常に自分が握り続けることを意識してみてください。
どなたかのお役に立てば幸いです。
それではまたー!